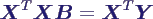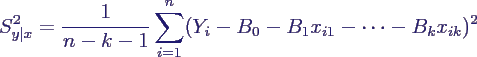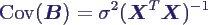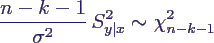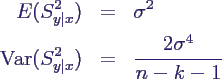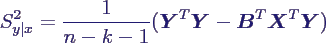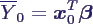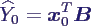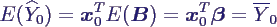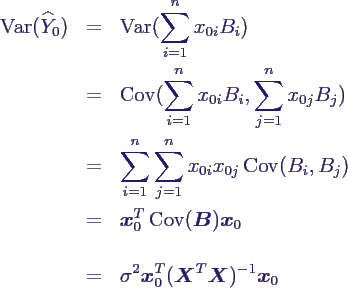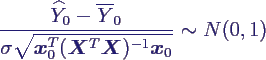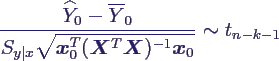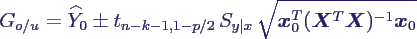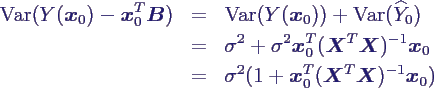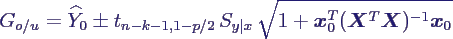Mehrfache lineare Regression
- Problemstellung:
- Größe y hängt (vermutlich) von
mehreren Einflussgrößen xi, i = 1 ... k, ab
- Zusammenhang wird als linear angenommen
- y = β0 + β1 x1
+ β2 x2 ... + βk
xk
- man macht n Messungen, um die p = k+1 unbekannten
Koeffizienten abzuschätzen (n > p) und erhält Werte yi,
xij (i = 1 ... n, j = 1 .. p-1)
- statistisches Modell
- Yi = β0 +
β1 x1 + β2 x2
... + βk xk + εi
- mit unabhängigen normalverteilten
Störungen εi ~ N(0, σ2)
- Einführen von Vektoren und Matrizen
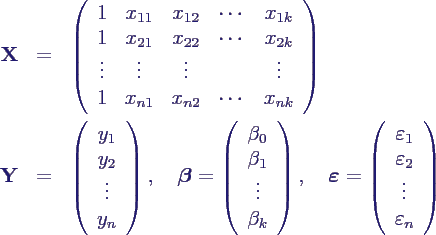
- liefert Gleichung des Modells
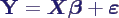
- Schätzer für die βi und σ2:
- Yi sind i.i.d. mit Yi ~
N(β0 + β1 x1 + ... +
βk xk, σ2)
- berechnen Maximum-Likelihood-Schätzer B
= (B0, B1, ..., Bk)T
für β ähnlich wie oben
- längere Rechnung liefert die Normalengleichung
- lineares Gleichungssytem mit p Gleichungen für p
Unbekannte
- XTX in der Regel
invertierbar (sonst schlechte Messreihe!)
- formale Lösung
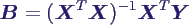
- numerisch lösen
- mit LU-Zerlegung (in Matlab: B
= (X'*X)\(X'*Y))
- nicht mit Berechnung der Inversen (in
Matlab: B = inv(X'*X)*(X'*Y))
- Schätzer für σ2
ähnlich wie oben
- Verteilung des Schätzers B:
- Linearkombinationen normalverteilter
Größen Yi → (multivariat) normalverteilt
- Erwartungswert
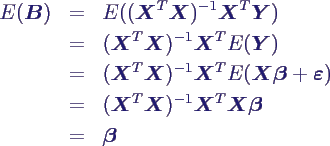
- → B ist erwartungstreu
- Kovarianzmatrix
- Verteilung des Schätzers S2y|x:
- ähnlich wie oben ist
- daher hat man
- außerdem gilt folgende nützliche Beziehung
zur Berechnung von S2y|x
- Prognose des Mittelwerts:
- Aufgabe: schätze aus den bekannten Daten X,
Y den Mittelwert von Y0 zu den Eingabewerten x0
= (1 x01 x02 ... x0k)T
- es ist
- Schätzer natürlich
- offensichtlich erwartungstreu
- interessant sind Streuung und Konfidenzintervalle
- als Linearkombination der Yi ist
 0 normalverteilt
0 normalverteilt
- Berechnung der Varianz
- insbesondere gilt
- ersetzt man σ2 durch seinen
Schätzer S2y|x, hat man wie immer
- daher erhält man Schätzer für ein
(1-p)-Konfindenzintervall um
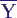 0
0
- Prognose eines Werts:
- schätze den Wert Y(x0) eines
Experiments mit Eingabewerten x0, nicht den
Mittelwert
- Schätzer bleibt gleich, aber Varianz ist
größer (wegen εi)
- Bi stammen aus bisherigen Daten, Y(x0)
bezieht sich auf neue → Bi und Y(x0)
sind unabhängig
- daher
- Schätzer für ein (1-p)-Konfindenzintervall
um Y(x0)
- Beispiel Härte von Stahl (nach [Ross2]):
- Stahlhersteller möchte kaltgewalzte Stahlbleche
mit Kupfergehalt qCu0 = 0.15 % und Glühtemperatur T0
= 620 °C herstellen
- gesucht ist Abschätzung der Härte hr0
(genauer: Rockwellhärte HR30T)
- folgende Daten sind bekannt
-
| T [°C] |
qCu [%] |
hr [HR30T] |
| 540 |
0.15 |
84.30 |
| 565 |
0.02 |
79.20 |
| 590 |
0.15 |
70.40 |
| 650 |
0.03 |
64.00 |
| 650 |
0.09 |
61.30 |
| 675 |
0.03 |
55.70 |
| 705 |
0.04 |
56.30 |
| 705 |
0.10 |
58.60 |
| 760 |
0.09 |
49.80 |
| 760 |
0.13 |
51.30 |
- Ansatz: multilineares Modell
- multilineares Regression liefert folgende
Schätzwerte
- B = [157.4; 16.60; -0.1450]
- sy|x = 3.223
- damit Schätzwert für gesuchte Härte
- 95%-Konfidenzintervall für den Mittelwert
- 95%-Konfidenzintervall für den Einzelwert
- Aufgaben: